
2019年10月18日,哈工大讯飞联合实验室(Joint Laboratory of HIT and iFLYTEK Research, HFL)与河北省讯飞人工智能研究院联合团队在由卡内基梅隆大学(CMU)、斯坦福大学和蒙特利尔大学联合发起的多步推理阅读理解评测HotpotQA中荣登榜首,全面刷新所有评测指标,其中综合模糊准确率(Joint F1)指标达到72.73。多步推理阅读理解评测HotpotQA自2018年发布以来吸引了大量高校和研究机构参与,其中包括微软、IBM研究院、上海交通大学、日本电报电话公司(NTT)、华盛顿大学等。

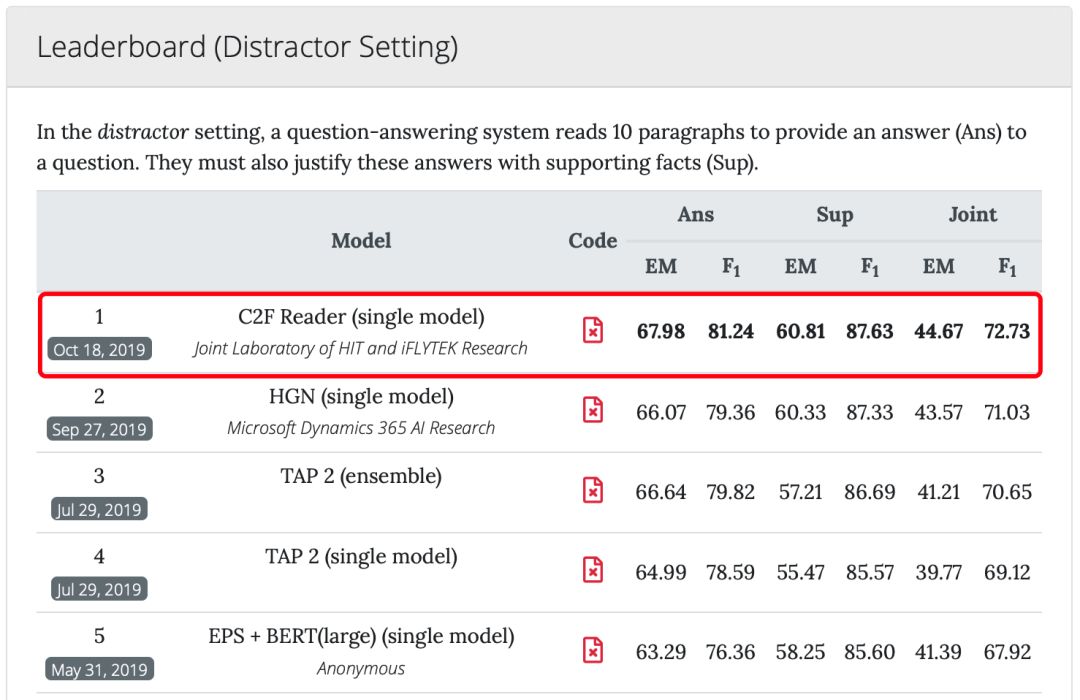
HotpotQA挑战赛(干扰项赛道)最新榜单(截止2019年10月24日)
2019年3月,哈工大讯飞联合实验室在国际权威阅读理解评测SQuAD 2.0中首次超过人类平均水平,意味着机器已经能够充分理解一般难度的文本语义,并准备向更高难度的文本理解任务发起挑战。传统的阅读理解数据集只需要理解单个篇章中与问题相关的某个特定篇章片段即可得到答案。而多步推理阅读理解评测HotpotQA不仅将模型需要“读”的文本范围扩展到了多个篇章段落,同时要从多个篇章中筛选出与问题相关的篇章,并进一步要求模型能够对佐证篇章中所叙述事物的逻辑关系构建两步及以上的推理链,因而更具有挑战性。HotpotQA评测根据提供的篇章数量分为两个赛道:干扰项赛道(Distractor Setting):每个问题提供10个备选篇章
全维基赛道(Fullwiki Setting):每个问题的备选篇章范围扩展到整个维基百科
本次哈工大讯飞联合实验室参加的是干扰项赛道(Distractor Setting),该赛道更侧重于考察模型的文本推理能力,同时也是参赛队伍最多的赛道。下图中给出了一个HotpotQA数据的示例,向机器询问“Rand Paul在2016年宣布竞选总统活动所在的酒店位于哪条河上?”。为了回答这个问题,机器需要首先从备选篇章中寻找到与问题相关的篇章。得到这些篇章后,我们从第一个篇章中得知该活动位于Galt House这家酒店。在阅读另一个篇章时,机器得知该Galt House这家酒店位于Ohio River上。最终,机器从这两条佐证证据(文章中绿色部分)推理得到答案“Ohio River”。
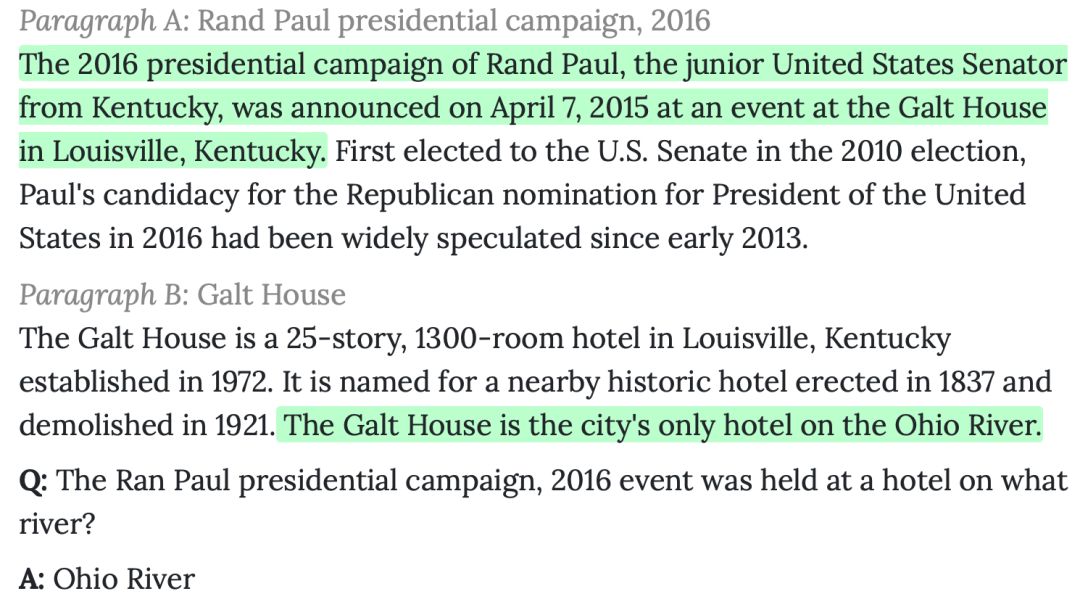
HotpotQA数据示例
其次,为了证明模型确实利用了原文中的相关证据进行推理并提升模型的可解释性,HotpotQA不仅要求模型给出最终答案,还要求模型给出推理所用到的佐证证据(Supporting Facts)。在评价指标上,HotpotQA评测会根据答案和佐证证据的精确匹配率(EM)和模糊匹配率(F1)求得最终的联合精确匹配率和模糊匹配率(Joint EM / F1)。从最终评测结果可以看出C2F Reader模型的得分显著高于榜单其他公开以及非公开的技术方案。
本次提交的C2F Reader(Coarse-to-Fine Reader)模型在结合了目前主流的基于预训练的语义表征模型BERT的基础上,针对需要多步推理的阅读理解任务进行了优化设计,主要包括以下三个特点:模型采用了由粗到细的架构(Coarse-to-Fine)设计。模型先通读多个篇章,寻找并挑选与问题最相关的内容进行精读,从而得到更为准确的答案。采用多任务学习(Multi-Task Learning)的方式,在逐步求精的计算过程中输出支持证据。最后基于所选择的支持证据寻找得到答案,使模型在提升准确率的同时拥有一定的可解释性。使用了预训练模型来进一步丰富文本的语义表示,同时应用了图神经网络(Graph Neural Network,GNN)模型来模拟人类在进行文本推理过程中从一个实体跳转到另一个实体的推理过程。
目前,人工智能正经历由感知智能向认知智能迈进的关键时期,为机器在理解文本语义的基础上进一步赋予推理能力对认知智能的研究和发展具有重大的意义。
>
持续推动中文信息处理技术发展哈工大讯飞联合实验室不仅在国际比赛中拔得头筹,也持续积极推动中文信息处理技术的研究与发展。2019年10月19日,由中国中文信息学会计算语言学专业委员会主办,哈工大讯飞联合实验室承办,科大讯飞股份有限公司冠名的第三届“讯飞杯”中文机器阅读理解评测研讨会(CMRC 2019)在云南昆明圆满落幕。至此,哈工大讯飞联合实验室已先后承办了三届“讯飞杯”中文机器阅读理解评测(CMRC)并且发布了相关中文阅读理解数据集,受到了业界广泛关注和各界研究人员的积极参加,进一步促进了中文机器阅读理解技术研究。

同时,为了进一步提升中文自然语言处理任务效果,哈工大讯飞联合实验室、认知智能国家重点实验室发布多种中文预训练模型,并且首次在CMRC 2018阅读理解挑战集的F1指标上超过60%,意味着中文预训练模型在困难问题上首次超过“及格线”。目前,哈工大讯飞联合实验室已发布的中文预训练模型有:BERT系列:BERT-wwm, BERT-wwm-ext
XLNet系列:XLNet-base, XLNet-mid
RoBERTa系列:RoBERTa-wwm-ext, RoBERTa-wwm-ext-large
>
哈工大讯飞联合实验室阅读理解团队(HFL-RC)哈工大讯飞联合实验室阅读理解团队(HFL-RC)是国内外最早启动机器阅读理解研究的团队之一,持续深耕机器阅读理解核心技术研究以及相关技术的产业落地。团队成立至今斩获了多项国际荣誉:
多次荣获国际权威机器阅读理解评测SQuAD 1.1冠军多次荣获国际权威机器阅读理解评测SQuAD 2.0冠军荣获国际语义评测SemEval 2018阅读理解任务冠军荣获对话型阅读理解评测CoQA冠军荣获对话型阅读理解评测QuAC冠军荣获多步推理阅读理解评测HotpotQA冠军
>
关于哈工大讯飞联合实验室哈工大讯飞联合实验室(HFL)是科大讯飞针对“讯飞超脑”项目计划,重点引进和布局的核心研发团队之一,由科大讯飞AI研究院与哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)共同创办。根据联合实验室建设规划,双方将在语言认知计算领域进行长期、深入合作,具体开展阅读理解、自动阅卷、类人答题、人机对话、语音识别后处理、社会舆情计算等前瞻课题的研究。重点突破深层语义理解、逻辑推理决策、自主学习进化等认知智能关键技术,支撑科大讯飞实现从“能听会说”到“能理解会思考”的技术跨越,并围绕教育、司法、人机交互等领域实现科研成果的规模化应用。
>
延伸阅读首超人类水平!哈工大讯飞联合实验室登顶机器阅读理解评测SQuAD 2.0哈工大讯飞联合实验室登顶对话型阅读理解挑战赛QuAC
哈工大讯飞联合实验室发布中文RoBERTa-large预训练模型
第三届CCL“讯飞杯”中文机器阅读理解评测研讨会圆满落幕
原文、编辑:HFL编辑部




